Decentralization is the new mantra in AI. Due to the explosive growth of mobile phones and other personal devices it has become necessary to deploy AI agents on small devices to provide better user experiences and protect sensitive personal data. However there are many challenges in achieving this goal. I will address two of the main challenges here and discuss how AI research is progressing towards finding a solution.
The first challenge is that Deep Neural Networks, the state of art machine learning models that power most of today’s AI agents, are computationally intensive to run on small devices. The second challenge, which is related to the first, is that it requires order of thousands of data points to train Deep Neural Networks which is typically not available on small devices.
Research to solve both these problems finds that Bayesian Inference, which is a branch of AI evolved from Bayesian Statistics, is a promising approach[1]. In a recent blogpost Qualcomm researchers have mentioned the advantages of using Bayesian Deep Learning for power efficient AI on mobile chips[2]. Currently this is demonstrated mainly for the computer vision domain applications such as classifying images and understanding scenes. This article describes some details of this method and how it can be generalized to other applications such as Behavioral Biometrics where Zighra is focussing. Our vision is to make Behavioral Biometrics based authentication entirely on device to protect privacy of users.
Let us look at how Bayesian inference can solve the first problem in this post. I will discuss how Bayesian methods can help in learning from small datasets in the second part of this blog post. The size of a DNN can be reduced during the training phase using a technique called Deep Compression[3]. This consists of 3 separate steps namely Pruning, Quantization of Weights and Huffman Coding. Pruning involves forcing the network to learn only the important connections. This reduces the number of connections typically by a factor of 10. During Quantization, weights are discretized which enables weight sharing between Neurons and helps to reduce the number of bits needed to store each connection. Huffman Coding is a lossless data compression algorithm where variable length codes are assigned to input characters of a string such that length of the codes are inversely proportional to frequencies of characters. Moreover the codes are from a family called Prefix Codes where no code is a prefix of another code in the sequence and the sequence is completely decodable. It was demonstrated that overall this approach can reduce the size of a network up to 50 times. In general the idea is to induce sparsity in the network architecture during the training phase of DNN which helps in avoiding overfitting of data through regularization, compression of the network and acceleration of the training itself.
Bayesian Inference provides a principled framework for training sparse DNN models such that the degree of sparsity can be tuned individually to each neuron or layer in a network. This approach was originated from the Sparse Bayesian Learning framework introduced by Tipping more than a decade ago[4]. To understand this better we need to get into some technical details of Bayesian inference.
Let D be a dataset containing N rows, each consisting of tuples xn,yn, where n=1,…,N. Goal is to predict value of y given a new observation x using the probability distribution p(y|x,w). Here w is parameter characterizing the distribution. In Bayesian approach one starts with a prior distribution p(w) for the parameter w which represents our prior knowledge or belief about the phenomena that we are modelling. After making some observations about the phenomena through data D, one update the belief through the well-known Bayesian theorem
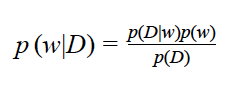
This process of estimating the posterior distribution from prior after receiving some data is called Bayesian Inference. This is not as simple as it sounds since usually it is very difficult to obtain the distribution p(D) analytically and one has to use approximate methods.
Standard approach to find posterior distribution is Markov Chain Monte Carlo Simulation aka MCMC. Recently another approach, called Variational Inference, is becoming very popular. Here the posterior distribution p(w|D) is approximated by a parametric distribution q(w). The optimal value of the variational parameter is found by minimizing the Lagrangian functional
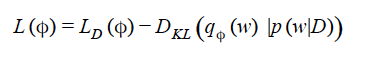
Here the first term on right hand side is the average value of log likelihood function taken over the distribution q(w) given by the equation:
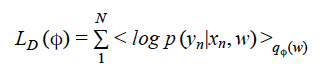
The sum is over the N data points in D. Second term is the Kullback-Leibler (KL) divergence, which is a measure of how good is the approximation q(w) to p(w|D). The minimization can be done very efficiently and in a scalable manner using a stochastic variational inference algorithm developed by Kingma and Welling[5]
So how one can use Bayesian Inference to reduce the size of Deep Neural Networks? It was shown by Geoffrey Hinton and team a few years back that if one multiplies weights of a neural network by a continuous noise N(1, alpha=p/1-p), where p is a parameter called drop out rate, it leads to effective regularization of the network and avoiding of overfitting[6]. The physical meaning of drop out is that during training some weights are set to zero with probability p. In the limit of p -> 1this implies that some weights are permanently set to zero or in other words removed from the network and hence a reduction in the network size. It can be shown that this can be cast as a Bayesian Inference problem with a specific prior distribution for the weights called improper log-uniform prior given by:
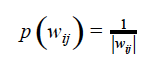
where wij is the weight of the link connecting Neurons i and j. Using this approach researchers have achieved close to 300 times reduction in the number of parameters on popular DNN architectures such as LeNet with insignificant reduction in accuracy[7]
These research findings are quite encouraging for implementing DNN models for behavioral biometrics based authentication completely on a device. The first step here is to demonstrate that DNNs are useful in processing time series data originating from smartphone sensors such as accelerometer and gyroscope and capable of identifying a user uniquely based on their usage of smartphones. Next step is to compress these DNN architectures using Bayesian compression scheme as explained in this post. Zighra AI team is working towards this direction to make AI completely decentralized and on-device for the protection of privacy of users.
Learn more about Zighra’s decentralized AI solutions:
References
- Bayesian Compression for Deep Learning, C. Louizos et.al., Proceedings of Neural Information Processing Systems Conference (NIPS), 2017
- How Algorithmic Advances Make Power Efficient AI Possible https://www.qualcomm.com/news/onq/2018/08/13/how-algorithmic-advances-make-power-efficient-ai-possible
- Deep Compression: Compressing Deep Neural Networks with pruning, training quantization and huffman coding. S. Han et.al., International Conference on Learning Representations (ICLR), 2016.
- Sparse Bayesian Learning and Relevance Vector Machine, ME Tipping, Journal of Machine Learning Research, 211–244, 2001.
- Auto Encoding Variational Bayes, D. P. Kingma et.al., International Conference on Learning Representations (ICLR), 2014.
- Dropout: A Simple Way to Prevent Neural Networks from Overfitting, Journal of Machine Learning Research, 1929−1958, 2014
- Variational Dropouts Sparsifies Deep Neural Networks, International Conference on Machine Learning (ICML), 2017